列見出しを順番に繰り出す
ワークシートの列位置を区別するシンボルを連続的に発生させるジェネレータ(Python の予約語:yield 式を持つ特殊な関数)を作りました。
コード
def xl_col_name_gen():
# 1st dimension (from A to Z)
for i in range(0x41, 0x5b):
yield '{:c}'.format(i)
# 2nd dimension (from AA to ZZ)
for i in range(0x41, 0x5b):
for j in range(0x41, 0x5b):
yield '{:c}{:c}'.format(i,j)
# 3rd dimension (from AAA to ZZZ)
for i in range(0x41, 0x5b):
for j in range(0x41, 0x5b):
for k in range(0x41, 0x5b):
yield '{:c}{:c}{:c}'.format(i,j,k)
この関数から最初に繰り出されるシンボルは’A'(0x41)で、Excel ワークシートの最も左側に位置する列を識別する為のものです。次に 繰り出されるのが’B’,順番に’C’,’D’,’E’‥と続き、’Z'(0x5a)まで繰り出されると次が’AA’に替わります。参照記事:ASCIIコード表
利用例
>>> gen = xl_col_name_gen()
>>> gen
<generator object xl_col_name_gen at 0x000001C788C98A50>
>>> next(gen)
'A'
>>> next(gen)
'B'
>>> next(gen)
'C'
>>> def func_A(gen):
... print(next(gen), next(gen), next(gen))
...
>>> def func_B(gen):
... print([item for item in gen])
...
>>> func_A(gen)
D E F
>>> func_B(gen)
['G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'AA', 'AB', 'AC', 'AD', 'AE', 'AF', 'AG', 'AH', 'AI', 'AJ', 'AK', 'AL', 'AM', 'AN', 'AO', 'AP', 'AQ', 'AR', 'AS', 'AT', 'AU', 'AV',
..... 途中略 .....
'YX', 'YY', 'YZ', 'ZA', 'ZB', 'ZC', 'ZD', 'ZE', 'ZF', 'ZG', 'ZH', 'ZI', 'ZJ', 'ZK', 'ZL', 'ZM', 'ZN', 'ZO', 'ZP', 'ZQ', 'ZR', 'ZS', 'ZT', 'ZU', 'ZV', 'ZW', 'ZX', 'ZY', 'ZZ', 'AAA', 'AAB', 'AAC', 'AAD', 'AAE',
..... 途中略 .....
'ZYW', 'ZYX', 'ZYY', 'ZYZ', 'ZZA', 'ZZB', 'ZZC', 'ZZD', 'ZZE', 'ZZF', 'ZZG', 'ZZH', 'ZZI', 'ZZJ', 'ZZK', 'ZZL', 'ZZM', 'ZZN', 'ZZO', 'ZZP', 'ZZQ', 'ZZR', 'ZZS', 'ZZT', 'ZZU', 'ZZV', 'ZZW', 'ZZX', 'ZZY', 'ZZZ']
>>>
説明
- Excel 作業を自動化するプログラムではランダムにセル番地を変える事はほとんどなく、列順アクセスなので、プログラムが見やすくする為ジェネレータを使いました。
- ジェネレータとせず、生成したシンボルをリストやタプルで戻すシンプルな方法もありますが、これだと 26 + (26*26) + (26*26*26) = 18278 バイトのストレージが必要です。ところがジェネレータでは next メソッドを呼び出すと、次の yield 式が現れるまで演算を実行するだけなので、追加のストレージが要らないのが特長です。
- このジェネレータで列名を表示させると ‘ZZZ’まで繰り出しますが、実際のところ「Excel の仕様と制限」のため、’XFD’ が利用可能な最大値です。
- 冒頭からの繰り出しを何回も繰り返したい場合は、次のコード例のように
gen = xl_col_name_gen()の代入を繰り返してください。
>>> gen = xl_col_name_gen()
>>> next(gen)
'A'
>>> next(gen)
'B'
>>> gen = xl_col_name_gen()
>>> next(gen)
'A'
>>> next(gen)
'B'
>>>
応用例(Pandas)
このジェネレータは科学実験やプログラムのテスト結果を Excel へまとめて保存しておきたい場合などに応用することが出来ます。
予想値と測定値(あるいは計算結果)が CSV やその他の手段を使い入手可能だとします。Pandas を使ってこのデータを処理し、分かったことを誰かへレポートする事例を想定してみます。参照記事:pandas documentation
import pandas as pd
df = pd.DataFrame({
# 2 番目のテストだけ NG という想定のサンプルデータ
'予想値': [ 543, 651, 995, 331 ],
'測定値': [ 543, 654, 995, 331 ],
})
報告する相手がエンジニアリング分野の方であれば次の計算結果を示せば結果を理解するはずです。
>>> df[df['予想値'] != df['測定値']]
予想値 測定値
1 651 654
>>>
プログラムのユニットテストであれば、例外をスローしてくれた方が都合がよく、無効同値クラスのテストが通った事をシンプルに証明できます。
>>> pd.testing.assert_series_equal(df['予想値'], df['測定値'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\someone\.venv\lib\site-packages\pandas\_testing\asserters.py", line 1077, in assert_series_equal
..... 途中略 .....
AssertionError: Series are different
Series values are different (25.0 %)
[index]: [0, 1, 2, 3]
[left]: [543, 651, 995, 331]
[right]: [543, 654, 995, 331]
>>>
上記の何れでもない場合は万人向けのまとめ方が必要です。そこで Excel を登場させます。
予想値と測定値を照し合せた結果を表示させる列の名前を仮に「判定」とします。
col_names = df.columns.tolist() + ['判定']
先のジェネレータ式を使って Excel のセルの列名を必要な数だけ繰り出します(事例では3つ。つまり’A’,’B’,’C’)。
gen = xl_col_name_gen()
ref_cols = [next(xl_col_name_gen) for i in range(len(col_names))]
「判定」列へ埋め込む Excel 計算式の元となるフォーマット文字列を用意します。波かっこで囲まれた部分へ、後述の format関数へ与えた引数があてがわれます。空の波かっこ部分にセルの列名、rownoを含む波かっこ部分にセルの行番号がそれぞれ埋め込まれる想定です。
expr_fmt = '=({}{rowno}={}{rowno})'
無名関数: f を定義します。これはデータセットの行数回呼び出され、セル番地を伴うExcel式を文字列として返します。引数の idx は DataFrame のインデックスが渡されます。定数 2 が足されている理由は、Excel の行番号が 1 から開始されることと、列名の行が 1 行分置かれているからです。
f = lambda idx: expr_fmt.format(*ref_cols[:], rowno=idx + 2)
セル番地による参照を含んだ Excel 計算式を「判定」列へ埋め込みます。-1 という添え字を与えるとリストの末尾に位置する要素が得られます。
df[col_names[-1]] = df.index.map(f)
上記に説明したコードを連続的に実行させた結果を例示します。
>>> # 判定用の Excel 計算式を置く列を含めた列リスト
>>> col_names = df.columns.tolist() + ['判定']
>>> gen = xl_col_name_gen()
>>>
>>> # 使われている列の数だけ Excel の列名を繰り出す
>>> # (この例では 'A','B','C' の各列)
>>> ref_cols = [gen) for i in range(len(col_names))]
>>>
>>> # Excel へ埋め込む判定式のフォーマット
>>> expr_fmt = '=({}{rowno}={}{rowno})'
>>>
>>> # expr_fmt のプレースフォルダへ値を埋め込む為のラムダ式
>>> # + 2 している理由は Pandas のインデックスが 0 から始まる
>>> # のと、列名の行が置かれる次の行から評価式が置かれる為。
>>> f = lambda idx: expr_fmt.format(*ref_cols[:], rowno=idx + 2)
>>>
>>> # 「判定」という名前の新しい列を DataFrame へ加えつつ、
>>> # 評価式を1行ずつ埋め込んでゆく
>>> df[col_names[-1]] = df.index.map(f)
>>>
DataFrame に何が保存されたか確認してみましょう。
>>> df
予想値 測定値 判定
0 543 543 =(A2=B2)
1 651 654 =(A3=B3)
2 995 995 =(A4=B4)
3 331 331 =(A5=B5)
>>>
このデータは Pandas の to_csv 関数を使うとファイルへ保存することが出来ます。データに日本語が含まれている場合、encodingを指定することで文字化けを防ぐことが出来ます。
df.to_csv('validate.csv',encoding='utf-8_sig', index = False)
保存された「validate.csv」というファイルをExcel へインポートしてみます。手順は次の通りです。
[メニュー]-[ファイル]-[開く]-《ダイアログから validate.csv を選択》-[テキストファイルウイザード1/3]-《”先頭行をデータの見出しとして使用する”をチェック。”次へ”》-[ テキストファイルウイザード2/3 ]-《”区切り文字”=”カンマ” 。”次へ” 》-[ テキストファイルウイザード3/3 ]-《”完了”》
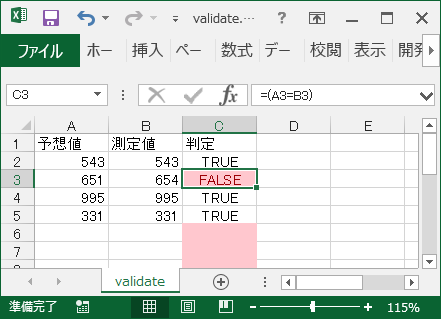
インポートしたデータがExcel へ表示されます。「判定」列へ埋め込んだ式がインポート時に計算されて「TRUE」または「FALSE」の表示になっている事と、2番目に表示されているNGだったテスト結果を反映して「判定」が「FALSE」になっている事がポイントです。
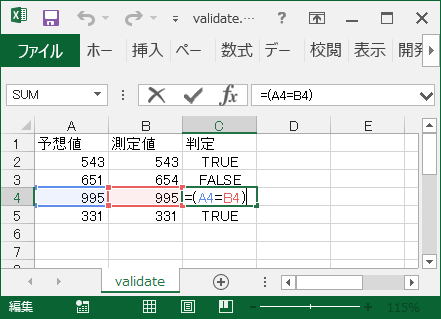
確認すべきデータが大量にあるときは Excel の視覚効果を利用する事も可能です。C列をマウスで全選択して次の手順で「FALSE」と表示されたセルを網掛けにすることが出来ます。
[メニュー]-[条件付き書式..]-[セルの強調表示ルール…]-[指定の値に等しい]-《”次の値に等しいセルを書式設定:”←”FALSE”》
これなら NG だったテストが直ぐに探し出し易くなります。