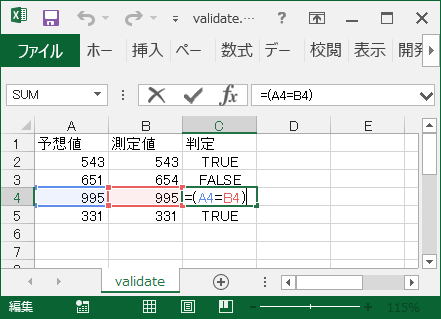
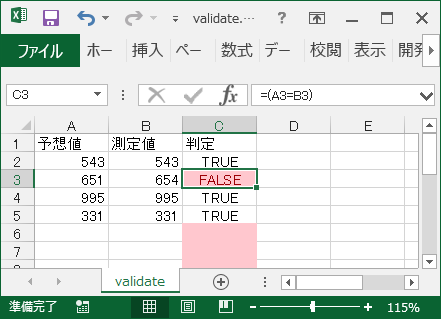
”符号無し整数で表現された日付”とは、例えば 2021年1月1日を 20210101 のような数値として表現するような方法の事です。
divmodというビルトイン関数が面白かったので応用例を作ってみました。コードは次の通りです。うるう年も考慮して結果を求めることが出来ます。
class date_as_integer:
"""符号無し整数で表現された日付に対する演算子をまとめたクラス
A class of operators for dates represented by unsigned integers
"""
@staticmethod
def add_days(orig_date, duration):
"""8か6桁の符号無し整数(yyyyMMdd か yyMMdd)で表現された
日付について、指定した日数を加算、または減算した結果を返す関数
A function implementation that returns the result of
adding or subtracting the specified number of days for a date
represented by an 8- or 6-digit unsigned integer (yyyyMMdd or yyMMdd).
"""
Y, _md = divmod(orig_date, 10000)
M, D = divmod(_md, 100)
M -= 1
D -= 1
def get_ndays_month(year):
months_of_year = [
[31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31], # not leap
[31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31] # leap year
]
return months_of_year[
year % 4 == 0 and (year % 100 != 0 or year % 400 == 0)
]
def future(ndays, duration, Y, M):
ndays = get_ndays_month(Y)[M]
M += 1
duration -= ndays
if M > 11:
M = 0
Y += 1
return ndays, duration, Y, M
def past(ndays, duration, Y, M):
M -= 1
ndays = get_ndays_month(Y)[M]
duration += ndays
if M < 0:
M = 11
Y -= 1
return ndays, duration, Y, M
step_into_next_month = future if (duration >= 0) else past
ndays = get_ndays_month(Y)[M]
while not ndays > (D + duration) >= 0:
ndays, duration, Y, M = step_into_next_month(ndays, duration, Y, M)
D += duration
return Y * 10000 + (M + 1) * 100 + D + 1
@staticmethod
def add_months(orig_date, duration):
"""6か4桁の符号無し整数(yyyyMM か yyMM)で表現された
日付について、指定した月数を加算、または減算した結果を返す関数
A function implementation that returns the result of
adding or subtracting the specified number of months for a date
represented by an 6- or 4-digit unsigned integer (yyyyMM or yyMM).
"""
Y0, M0 = divmod(int(orig_date), 100)
dy, dm = divmod(duration, 12)
if M0 + dm > 12:
Y1 = Y0 + dy + 1
M1 = M0 + dm - 12
else:
Y1 = Y0 + dy
M1 = M0 + dm
return Y1 * 100 + M1
if __name__ == "__main__":
print('Up and Down at new year boundary')
for i in range(2):
print(date_as_integer.add_days(20211231, i))
for i in range(2):
print(date_as_integer.add_days(20220101, -i))
print('At boundary of leap day every 4 years')
for i in range(3):
print(date_as_integer.add_days(20200228, i))
for i in range(3):
print(date_as_integer.add_days(20200301, -i))
print('''At boundary of leap day in a year that cannot divide by 100
(28 days are in February) ''')
for i in range(2):
print(date_as_integer.add_days(21000228, i))
for i in range(2):
print(date_as_integer.add_days(21000301, -i))
print('''At boundary of leap day in a year that can divide by 400
(29 days are in February) ''')
for i in range(3):
print(date_as_integer.add_days(20000228, i))
for i in range(3):
print(date_as_integer.add_days(20000301, -i))
print('Find the date N months later (or earlier)')
for i in range(2):
print(date_as_integer.add_months(200012, i))
for i in range(2):
print(date_as_integer.add_months(200101, -i))
print('38 == 6 + 12 + 12 + 8')
print(date_as_integer.add_months(200006, 38))
print(date_as_integer.add_months(200006, -38))
実行すると次の様な表示結果を得ます。
Up and Down at new year boundary
20211231
20220101
20220101
20211231
At boundary of leap day every 4 years
20200228
20200229
20200301
20200301
20200229
20200228
At boundary of leap day in a year that cannot divide by 100
(28 days are in February)
21000228
21000301
21000301
21000228
At boundary of leap day in a year that can divide by 400
(29 days are in February)
20000228
20000229
20000301
20000301
20000229
20000228
Find the date N months later (or earlier)
200012
200101
200101
200012
38 == 6 + 12 + 12 + 8
200308
199704